Academic Image Similarity Search
This project focuses on building an image similarity search system using images extracted from academic papers published by Can Tho University. Each image is stored together with metadata such as paper title, authors, page number, and DOI. Deep learning models including VGG16, ConvNeXt V2, and AlexNet are used for image classification and feature extraction. The extracted embeddings are indexed using FAISS to enable efficient similarity search. Due to the limited dataset size (4,303 images across 11 classes), some inaccuracies remain, but the system demonstrates strong potential for supporting image similarity detection in academic publishing.
| Role | Fullstack Developer | Individual Research Project |
| Duration | 06/2025 – 08/2025 |
| Main Technology | Python Django ReactJS TensorFlow FAISS MySQL PyTorch |
Automatically extracts images from academic PDF papers.
Applies VGG16, ConvNeXt V2, and AlexNet for feature extraction.
Uses FAISS for similarity indexing and search.
Supports classification across 11 academic image classes.
How It Looks
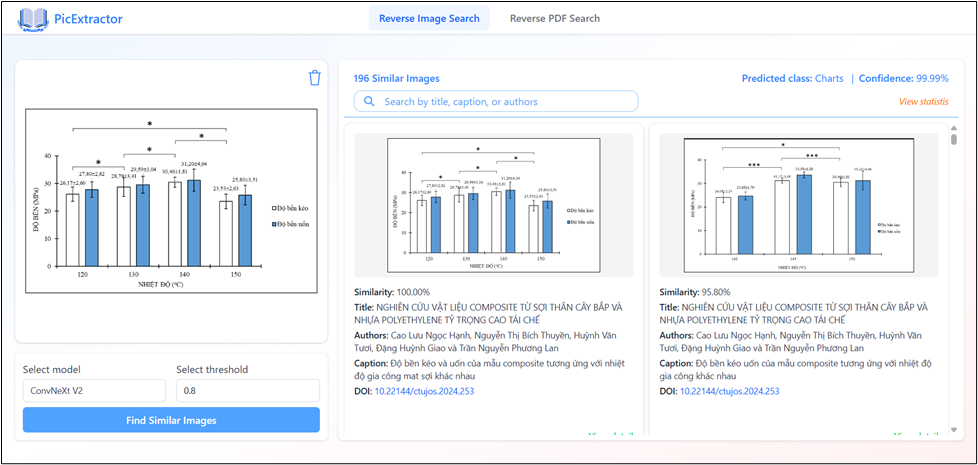
The image similarity search interface allows users to upload a query image and automatically retrieve visually similar images from the academic dataset. Results are ranked based on similarity scores computed from deep feature embeddings, supporting efficient detection of duplicate or near-duplicate images
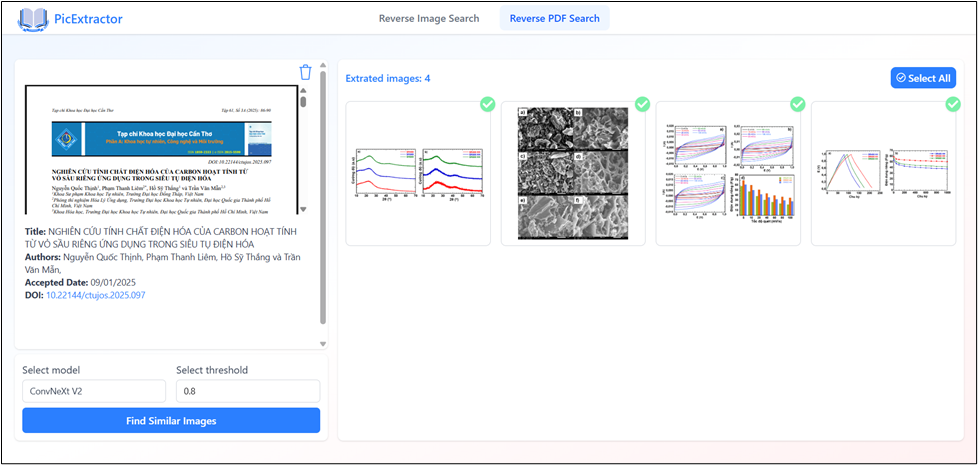
This interface allows users to upload an academic PDF paper formatted according to the publication standards of Can Tho University. The system automatically extracts images from the document and presents them for selection. Users can choose a specific extracted image, select a deep learning model (VGG16, ConvNeXt V2, or AlexNet), and adjust the similarity threshold to control the strictness of the image retrieval process.
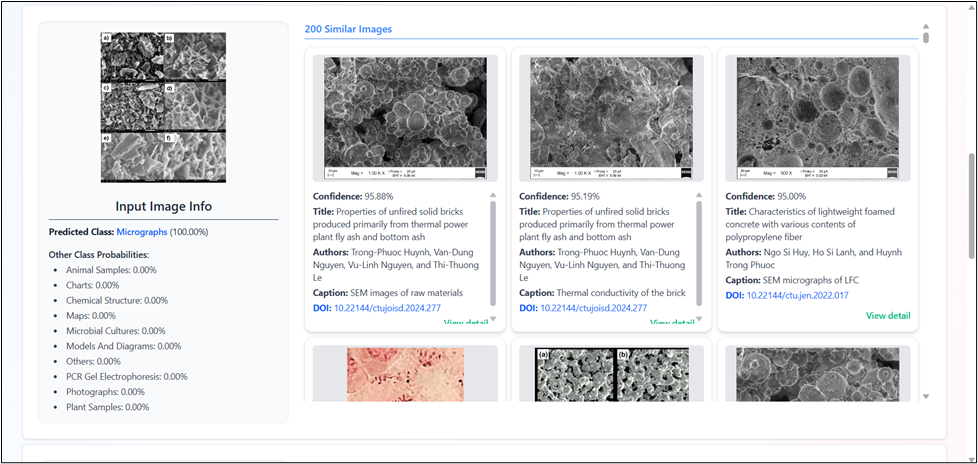
The results interface displays retrieved images grouped by predicted classes. Each image is accompanied by detailed academic metadata, including the source paper information such as title, authors, page number, and DOI. This presentation enables users to not only assess visual similarity but also trace each image back to its original academic publication, supporting efficient verification and analysis in scientific document review
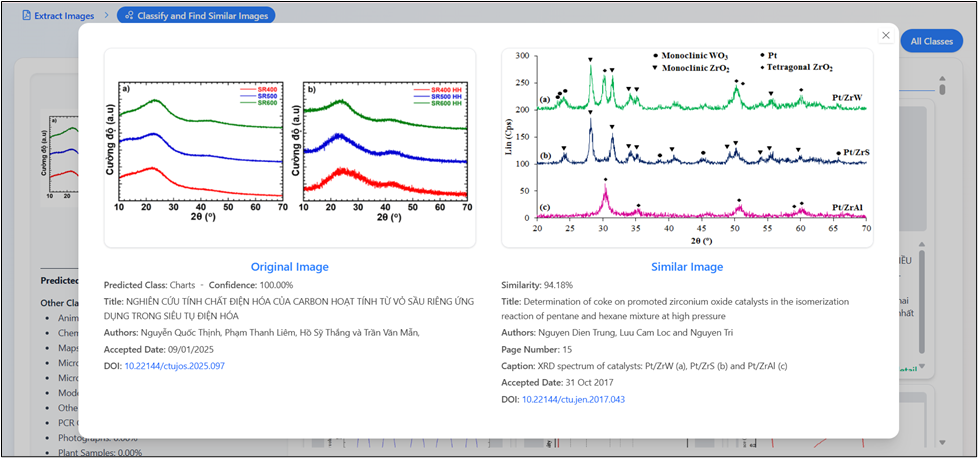
This view presents a side-by-side comparison between the query image extracted from an academic paper and the retrieved similar image. Detailed metadata for both images is displayed, enabling direct comparison of source information such as publication details, page numbers, and identifiers. By providing both visual similarity and contextual academic information, the system supports accurate verification and analysis of potential image reuse across scientific publications.
This view provides a statistical overview of academic papers that contain the highest number of visually similar images. The results are aggregated by publication, allowing users to quickly identify papers with a high frequency of potential image reuse. Such statistics support large-scale screening and help reviewers prioritize documents for further manual inspection in academic publishing workflows